La contenedorización es una forma popular de implementar aplicaciones, muchas empresas utilizan esta forma para ejecutar sus servicios. Como entusiasta de la seguridad o Red Teamer, se vuelve necesario saber cómo funcionan los contenedores y cómo acceder a ellos. Aprenda los conceptos básicos de la creación de contenedores en el contexto de Docker y cómo hackearlos.

Los contenedores no son realmente una cosa, se crean utilizando funciones del kernel de Linux, como espacios de nombres y cgroups, que permiten la creación de entornos aislados para ejecutar aplicaciones. Estos entornos aislados, o contenedores, pueden incluir sus propias bibliotecas del sistema, archivos y configuraciones de red, lo que les permite funcionar como si estuvieran separados del sistema host.
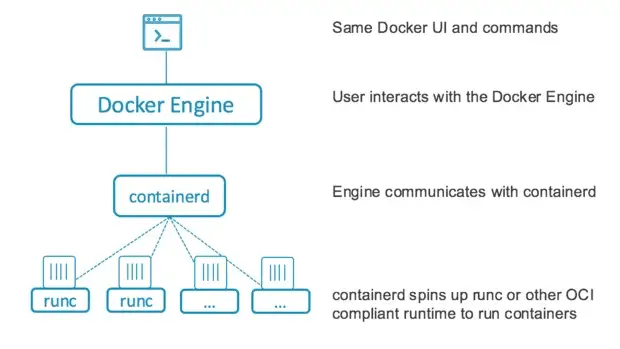
Arquitectura básica de la ventana acoplable
- containerd es un tiempo de ejecución de contenedores que puede administrar un ciclo de vida completo de contenedores, desde la transferencia/almacenamiento de imágenes hasta la ejecución, supervisión y redes de contenedores.
- container-shim maneja contenedores sin cabeza, lo que significa que una vez que runc inicializa los contenedores, sale y entrega los contenedores a container-shim, que actúa como un intermediario.
- runc es un contenedor de tiempo de ejecución universal ligero, que cumple con la especificación OCI. containerd utiliza runc para generar y ejecutar contenedores de acuerdo con las especificaciones de OCI. También es el reenvasado de libcontainer.
- grpc utilizado para la comunicación entre containerd y docker-engine.
- OCI mantiene la especificación OCI para tiempo de ejecución e imágenes. Las versiones actuales de Docker admiten imágenes OCI y especificaciones de tiempo de ejecución.
Entre bastidores
Docker ha abstraído el proceso de creación de un entorno aislado para ejecutar aplicaciones, ha hecho que sea bastante fácil generar un contenedor que está separado del host, pero si observa de cerca, hay muchas cosas que suceden en segundo plano. El proceso general se parece a esto
- El demonio Docker inicia el proceso del contenedor.
- Si es necesario, la imagen especificada para el contenedor se descarga desde Docker Hub.
- La llamada al sistema para dejar de compartir crea un nuevo espacio de nombres para el contenedor.
- La llamada al sistema de bifurcación crea un nuevo proceso dentro del nuevo espacio de nombres.
- El contenedor se ejecuta mediante llamadas al sistema como exec, kill y waitpid para administrar los procesos dentro del contenedor.
Para comprender mejor la contenedorización, es importante familiarizarse con cierta terminología básica.
Los espacios de nombres
Los espacios de nombres de Linux (ns) son construcciones a nivel de kernel que permiten el aislamiento de los recursos del sistema global, como las interfaces de red, los ID de proceso y los puntos de montaje.
Cada espacio de nombres tiene su propio conjunto de recursos del sistema, como interfaces de red, ID de proceso y puntos de montaje. Esto permite que los procesos se aíslen unos de otros para que no puedan interferir o manipular los recursos de otros procesos.
Hay varios tipos diferentes de espacios de nombres en Linux, cada uno de los cuales proporciona una vista privada de un tipo diferente de recurso del sistema:
- Espacios de nombres PID: los procesos dentro de un espacio de nombres PID tienen su propio conjunto privado de ID de proceso, que son independientes de los ID de proceso de los procesos fuera del espacio de nombres. Esto permite que varios procesos tengan el mismo ID de proceso sin entrar en conflicto entre sí.
- Espacios de nombres UTS: los espacios de nombres UTS proporcionan una vista privada del nombre de host y el nombre de dominio para un proceso.
- Espacios de nombres de IPC: los espacios de nombres de IPC proporcionan una vista privada de los recursos de comunicación entre procesos (IPC), como colas de mensajes y semáforos.
- Espacios de nombres de red: los espacios de nombres de red proporcionan una vista privada de las interfaces de red, rutas y reglas de firewall. Esto permite que los procesos dentro de un espacio de nombres tengan su propia pila de red virtual, que es independiente de la pila de red del sistema host.
- Espacios de nombres de montaje: los espacios de nombres de montaje proporcionan una vista privada de la jerarquía del sistema de archivos. Los procesos dentro de un espacio de nombres de montaje tienen su propio conjunto privado de puntos de montaje.
Puede verificar los espacios de nombres de un proceso usando ls -l /proc//ns .
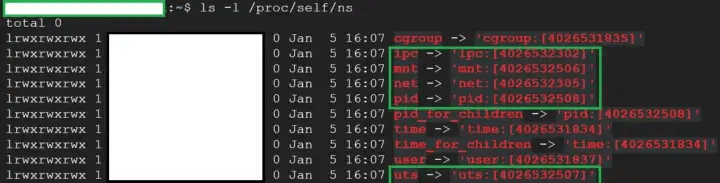
1150 es el PID de un proceso ejecutado desde dentro del contenedor
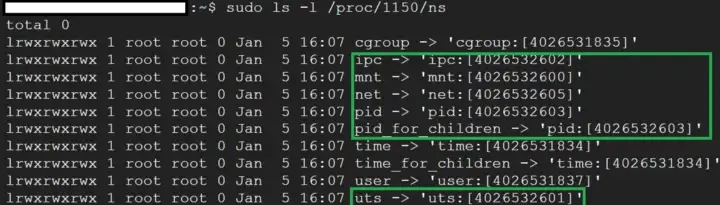
Algunos espacios de nombres del host y el contenedor siguen siendo los mismos, ya que no es necesario aislarlos. También podemos crear espacios de nombres separados para ellos.
También podemos usar el comando unshare, permite ejecutar un proceso o comando en un nuevo espacio de nombres.

Aquí ejecutamos el comando unshare para generar /bin/bash en un nuevo espacio de nombres PID (-p). -f se usa para bifurcar el programa especificado como un proceso secundario de no compartir en lugar de ejecutarlo directamente.
ps aux muestra que solo se están ejecutando 2 procesos, pero en realidad, estos procesos se están ejecutando dentro de un nuevo espacio de nombres y no pueden ver otros procesos del sistema host.
cgrupos
Los grupos de control (cgroups) son una característica de Linux que le permite establecer límites en los recursos que los procesos pueden usar y asignar estos recursos a contenedores, procesos o grupos de procesos. cgroups proporciona la funcionalidad principal que permite que docker funcione.
Divide los recursos del sistema en grupos de control con límites de recursos específicos y asigna procesos a estos grupos para priorizar ciertos procesos y ajustar la asignación de recursos.
Podemos lanzar un contenedor Docker con límites en la cantidad de procesos o la cantidad de memoria que el contenedor puede usar.
Podemos lanzar un contenedor Docker con límites en la cantidad de procesos o la cantidad de memoria que el contenedor puede usar.
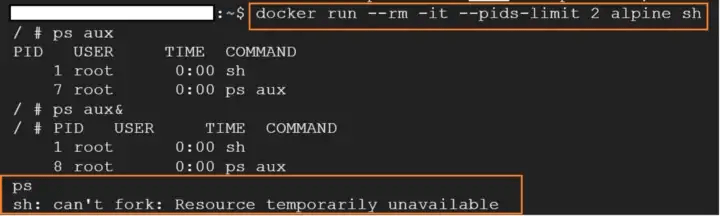
Aquí configuramos la cantidad de procesos en 2, si iniciamos más de 2 procesos, obtenemos un error. Esto cobra importancia si queremos prevenir ataques que consuman recursos del sistema.
Capacidades de Linux
En Linux, las capacidades son una forma de dividir los privilegios asociados con el acceso de superusuario (raíz) en un conjunto de unidades distintas que se pueden habilitar o deshabilitar de forma independiente. Esto le permite dar acceso a ciertos programas a ciertos privilegios sin darles acceso completo a la raíz.
En el contexto de Docker, las capacidades de Linux se pueden usar para permitir que un contenedor realice ciertas acciones privilegiadas que normalmente estarían restringidas al usuario raíz del sistema operativo host.
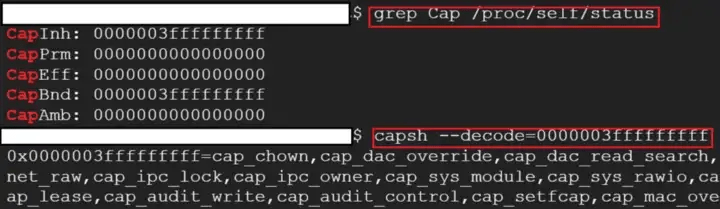
Limitación de llamadas al sistema con seccomp
Seccomp (abreviatura de “Modo informático seguro”) es una función del kernel que permite que una aplicación especifique un filtro para las llamadas al sistema que puede realizar. Esto se puede usar para restringir el acceso de la aplicación al sistema, a fin de aumentar la seguridad general del sistema.
seccomp se puede utilizar para restringir aún más el acceso de una aplicación en contenedor al sistema host. De forma predeterminada, los contenedores Docker tienen acceso a todas las mismas llamadas al sistema que el sistema host, pero esto se puede cambiar especificando un perfil seccomp al iniciar el contenedor.
Perfil seccomp básico que bloquea la llamada al sistema de desvinculación:

AppArmor
AppArmor es un módulo de seguridad de Linux que permite a los administradores especificar reglas sobre cómo las aplicaciones pueden acceder a los recursos en el sistema host.
En el contexto de Docker, AppArmor se puede utilizar para proteger los contenedores mediante la especificación de reglas que restringen las acciones que puede realizar una aplicación en contenedores.
Por ejemplo, la siguiente regla permitirá el acceso limitado a los archivos mencionados

Analicemos ahora los posibles vectores de ataque que se pueden usar para hackear un contenedor docker.
Abusar del modo privilegiado
El indicador –privileged en Docker se usa para otorgar a un contenedor acceso completo a los recursos del sistema host. Cuando se ejecuta un contenedor con esta marca, tiene los mismos privilegios que el sistema host y puede realizar cualquier acción que el host pueda.
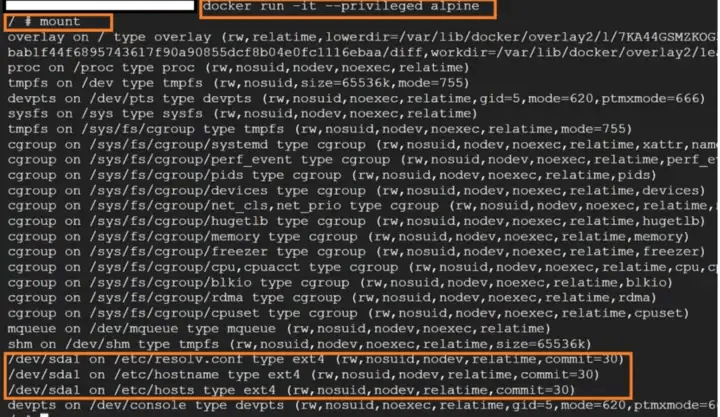
Dado que este contenedor se ejecuta con el indicador privilegiado, deshabilita los mecanismos de aislamiento y seguridad. Ahora podemos usar el comando de montaje para montar el sistema de archivos del host dentro del contenedor y leer/escribir/actualizar archivos.

Configuraciones incorrectas del socket Docker
El socket de Docker se utiliza como canal de comunicación entre el cliente de Docker y el demonio (servidor) de Docker.
Las configuraciones incorrectas del socket de Docker pueden representar un riesgo de seguridad porque pueden permitir el acceso no autorizado al demonio de Docker. El demonio Docker es responsable de administrar y ejecutar contenedores y tiene acceso a todos los recursos del sistema host.

Puede buscar docker.sock el archivo dentro de un contenedor, estos archivos de socket generalmente se cargan dentro del contenedor mientras se inician. Con esto, puede crear nuevos contenedores o eliminar los existentes.
Explotación de vulnerabilidades del Kernel
Unas de las vulnerabilidades de seguridad importantes que tiene Docker es que comparte el mismo kernel con el host, lo que lo hace explotable con las mismas vulnerabilidades en las que se ve afectado el kernel del sistema host.
Puede escanear el contenedor en busca de vulnerabilidades del kernel utilizando herramientas como LinPEAS
API REST HTTP de Docker sin autenticar
Si la API REST HTTP de un demonio Docker no está autenticada, significa que cualquier persona puede acceder y potencialmente controlar el demonio Docker de forma remota a través de la red sin necesidad de un nombre de usuario o contraseña.
De forma predeterminada, la API REST de docker es una API no autenticada, lo que significa que cualquier persona en la red puede iniciar y detener un contenedor.
En su mayoría, el servicio se ejecuta en el puerto 2376 pero también puede escanear el host local para verificar si hay puertos abiertos.

Sin segregación de red
De forma predeterminada, todos los contenedores de la red pueden comunicarse entre sí y no existe segregación entre ellos.
Sin embargo, docker proporciona tres tipos de mecanismos de comunicación de red.
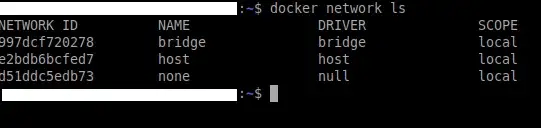
Ninguno
Cuando ejecutamos el contenedor en modo ninguno, el contenedor docker se ejecuta en un entorno aislado. Todo el tráfico entrante y saliente será bloqueado

Revisión de Dockerfile
Los Dockerfiles son la base para construir un contenedor, y es importante tener en cuenta la seguridad al crearlos, algunas de las cosas que se deben tener en cuenta son:
- Exponer puertos innecesarios: asegúrese de que solo estén expuestos los puertos necesarios para que la aplicación funcione.
- Ejecución de contenedores como raíz: de forma predeterminada, los contenedores se ejecutan como raíz, lo que puede ser un riesgo para la seguridad. En su lugar, cree un usuario que no sea root en Dockerfile y utilícelo para ejecutar la aplicación.
- No especificar límites de recursos: sin límites de recursos, un contenedor podría consumir potencialmente todos los recursos del host y provocar una denegación de servicio.
- Uso de imágenes base desactualizadas: las imágenes base que están desactualizadas pueden contener vulnerabilidades que se pueden aprovechar.
- No manejar correctamente los secretos: a veces puede encontrar claves API y tokens secretos incrustados dentro del Dockerfile
- No habilitar las funciones de seguridad: asegúrese de que las funciones de seguridad, como AppArmor y seccomp, estén habilitadas para ayudar a proteger el contenedor.
- Estas son algunas de las técnicas que puede usar para hackear dentro de un contenedor docker. Hay muchas otras cosas que puedes probar, te recomiendo que investigues por tu cuenta y practiques.
El cargo Guía para asegurar contenedores, dockers y microservicios en la nube apareció primero en Noticias de seguridad informática, ciberseguridad y hacking.
Ver Fuente
No hay comentarios.:
Publicar un comentario