En el panorama de la inteligencia artificial en rápida evolución, los sistemas de IA generativa se han convertido en una piedra angular de la innovación, impulsando avances en campos que van desde el procesamiento del lenguaje hasta la generación de contenido creativo. Sin embargo, un informe reciente del Instituto Nacional de Estándares y Tecnología (NIST) arroja luz sobre la creciente vulnerabilidad de estos sistemas a una variedad de ciberataques sofisticados. El informe proporciona una taxonomía completa de los ataques dirigidos a sistemas de IA generativa (GenAI), y revela las formas intrincadas en las que se pueden explotar estas tecnologías. Los hallazgos son particularmente relevantes a medida que la IA continúa integrándose más profundamente en varios sectores, lo que genera preocupaciones sobre las implicaciones de integridad y privacidad de estos sistemas.
ATAQUES A LA INTEGRIDAD: UNA AMENAZA AL NÚCLEO DE LA IA
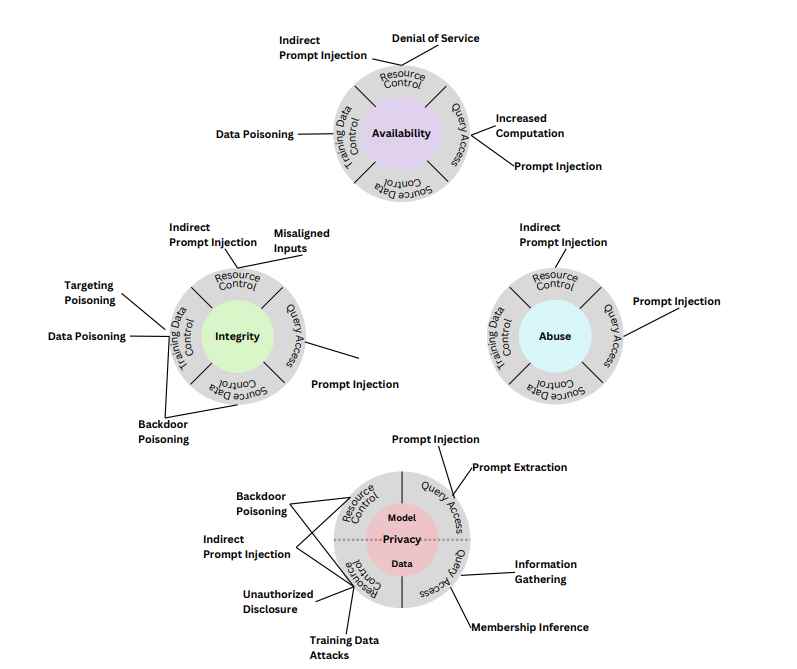
Los ataques a la integridad que afectan a los sistemas de IA generativa son un tipo de amenaza a la seguridad cuyo objetivo es manipular o corromper el funcionamiento del sistema de IA. Estos ataques pueden tener implicaciones importantes, especialmente porque los sistemas de IA generativa se utilizan cada vez más en diversos campos. A continuación se muestran algunos aspectos clave de los ataques a la integridad de los sistemas de IA generativa:
- Envenenamiento de datos :
- Detalle: este ataque tiene como objetivo la fase de entrenamiento de un modelo de IA. Los atacantes inyectan datos falsos o engañosos en el conjunto de entrenamiento, lo que puede alterar sutil o significativamente el aprendizaje del modelo. Esto puede dar como resultado un modelo que genere resultados sesgados o incorrectos.
- Ejemplo: considere un sistema de reconocimiento facial que se entrena con un conjunto de datos que ha sido envenenado con imágenes sutilmente alteradas. Estas imágenes pueden contener pequeños cambios imperceptibles que hacen que el sistema reconozca incorrectamente ciertas caras u objetos.
- Manipulación del modelo :
- Detalle: En este ataque se alteran los parámetros internos o la arquitectura del modelo de IA. Esto podría hacerlo una persona interna con acceso al modelo o explotando una vulnerabilidad en el sistema.
- Ejemplo: un atacante podría alterar las ponderaciones en un modelo de análisis de sentimientos, haciendo que interprete los sentimientos negativos como positivos, lo que podría ser particularmente dañino en contextos como el análisis de comentarios de los clientes.
- Manipulación de salida :
- Detalle: esto ocurre en el posprocesamiento, donde la salida de la IA se intercepta y modifica antes de que llegue al usuario final. Esto se puede hacer sin alterar directamente el modelo de IA.
- Ejemplo: si se utiliza un sistema de IA generativa para generar informes financieros, un atacante podría interceptar y manipular el resultado para mostrar una salud financiera incorrecta, lo que afectaría los precios de las acciones o las decisiones de los inversores.
- Ataques adversarios :
- Detalle: Estos ataques utilizan entradas que están diseñadas específicamente para confundir el modelo de IA. Estas entradas a menudo son indistinguibles de las entradas normales del ojo humano, pero provocan que la IA cometa errores.
- Ejemplo: una señal de alto con pegatinas o grafitis sutiles podría ser reconocida como una señal de límite de velocidad por el sistema de inteligencia artificial de un vehículo autónomo, lo que daría lugar a posibles infracciones de tráfico o accidentes.
- Ataques de puerta trasera :
- Detalle: Se integra una puerta trasera en el modelo de IA durante su entrenamiento. Esta puerta trasera se activa mediante determinadas entradas, lo que hace que el modelo se comporte de forma inesperada o maliciosa.
- Ejemplo: un modelo de traducción de idiomas podría tener una puerta trasera que, cuando se activa con una frase específica, comienza a insertar o alterar palabras en una traducción, lo que potencialmente cambia el significado del mensaje.
- Explotación de prejuicios :
- Detalle: este ataque aprovecha los sesgos existentes dentro del modelo de IA. Los sistemas de IA pueden heredar sesgos de sus datos de entrenamiento, y estos sesgos pueden explotarse para producir resultados sesgados o dañinos.
- Ejemplo: si un modelo de IA utilizado para la selección de currículums tiene un sesgo de género inherente, los atacantes pueden enviar currículums diseñados para explotar este sesgo, lo que aumenta la probabilidad de que ciertos candidatos sean seleccionados o rechazados injustamente.
- Ataques de evasión :
- Detalle: en este escenario, los datos de entrada se manipulan de tal manera que el sistema de inteligencia artificial no logra reconocerlos como algo para lo que está entrenado para detectar o categorizar correctamente.
- Ejemplo: El malware podría diseñarse para evadir la detección de un sistema de seguridad basado en IA alterando ligeramente la firma de su código, haciéndolo parecer benigno para el sistema y al mismo tiempo llevando a cabo funciones maliciosas.
ATAQUES A LA PRIVACIDAD DE LA IA GENERATIVA
Los ataques a la privacidad de los sistemas de IA generativa son una preocupación seria, especialmente dado el uso cada vez mayor de estos sistemas en el manejo de datos confidenciales. Estos ataques tienen como objetivo comprometer la confidencialidad y privacidad de los datos utilizados o generados a partir de estos sistemas. A continuación se muestran algunos tipos comunes de ataques a la privacidad, explicados en detalle con ejemplos:
- Ataques de inversión de modelos :
- Detalle : en este tipo de ataque, el atacante intenta reconstruir los datos de entrada a partir de la salida del modelo. Esto es particularmente preocupante si el modelo de IA genera algo que indirectamente revela información confidencial sobre los datos de entrada.
- Ejemplo : considere un sistema de reconocimiento facial que genera la probabilidad de ciertos atributos (como la edad o el origen étnico). Un atacante podría utilizar esta información de salida para reconstruir los rostros de las personas en los datos de entrenamiento, invadiendo así su privacidad.
- Ataques de inferencia de membresía :
- Detalle : estos ataques tienen como objetivo determinar si un registro de datos en particular se utilizó en el conjunto de datos de entrenamiento de un modelo de aprendizaje automático. Esto puede representar un problema de privacidad si los datos de capacitación contienen información confidencial.
- Ejemplo : un atacante podría probar una herramienta de diagnóstico de salud de IA con datos específicos de un paciente. Si las predicciones del modelo son inusualmente precisas o ciertas, podría indicar que los datos del paciente formaban parte del conjunto de entrenamiento, lo que podría revelar información de salud confidencial.
- Extracción de datos de entrenamiento :
- Detalle : aquí, el atacante pretende extraer puntos de datos reales del conjunto de datos de entrenamiento del modelo de IA. Esto se puede lograr analizando las respuestas del modelo a diversas entradas.
- Ejemplo : un atacante podría interactuar con un modelo de lenguaje entrenado en documentos confidenciales y, mediante consultas cuidadosamente elaboradas, podría hacer que el modelo regurgite fragmentos de estos textos confidenciales.
- Ataques de reconstrucción :
- Detalle : similar a la inversión del modelo, este ataque se centra en reconstruir los datos de entrada, a menudo de forma detallada y de alta fidelidad. Esto es particularmente factible en modelos que retienen mucha información sobre sus datos de entrenamiento.
- Ejemplo : en un modelo generativo entrenado para producir imágenes basadas en descripciones, un atacante podría encontrar una manera de ingresar indicaciones específicas que hagan que el modelo genere imágenes muy parecidas a las del conjunto de entrenamiento, lo que podría revelar imágenes privadas o confidenciales.
- Ataques de inferencia de propiedad :
- Detalle : estos ataques tienen como objetivo inferir propiedades o características de los datos de entrenamiento que el modelo no pretendía revelar. Esto podría exponer atributos o tendencias confidenciales en los datos.
- Ejemplo : un atacante podría analizar el resultado de un modelo utilizado para evaluaciones de desempeño de los empleados para inferir características desprotegidas de los empleados (como género o raza), que podrían usarse con fines discriminatorios.
- Robo o extracción de modelos :
- Detalle : en este caso, el atacante pretende replicar la funcionalidad de un modelo de IA propietario. Al consultar ampliamente el modelo y observar sus resultados, el atacante puede crear un modelo similar sin acceso a los datos de entrenamiento originales.
- Ejemplo : un competidor podría utilizar la API pública de un modelo de aprendizaje automático para consultarlo sistemáticamente y utilizar las respuestas para entrenar un nuevo modelo que imite el original, robando efectivamente la propiedad intelectual.
SEGMENTACIÓN
Los ataques a sistemas de IA, incluido ChatGPT y otros modelos de IA generativa, se pueden categorizar aún más según la etapa del proceso de aprendizaje al que se dirigen (entrenamiento o inferencia) y el conocimiento y el nivel de acceso del atacante (caja blanca o caja negra). Aquí hay un desglose:
POR ETAPA DE APRENDIZAJE:
- Ataques durante la fase de entrenamiento :
- Envenenamiento de datos : inyectar datos maliciosos en el conjunto de entrenamiento para comprometer el proceso de aprendizaje del modelo.
- Ataques de puerta trasera : incorporar funcionalidades ocultas en el modelo durante el entrenamiento que pueden activarse mediante entradas específicas.
- Ataques durante la fase de inferencia :
- Ataques adversarios : presentar entradas engañosas para engañar al modelo y hacer que cometa errores durante su operación.
- Ataques de inversión y reconstrucción de modelos : intentar inferir o reconstruir datos de entrada a partir de las salidas del modelo.
- Ataques de inferencia de membresía : determinar si se utilizaron datos específicos en el conjunto de entrenamiento observando el comportamiento del modelo.
- Ataques de inferencia de propiedad : inferir propiedades de los datos de entrenamiento que no están destinadas a ser divulgadas.
- Manipulación de salida : alterar la salida del modelo después de que se haya generado pero antes de que llegue al destinatario previsto.
POR CONOCIMIENTO Y ACCESO DEL ATACANTE:
- Ataques de caja blanca (el atacante tiene pleno conocimiento y acceso):
- Model Tampering : Alteración directa de los parámetros o estructura del modelo.
- Ataques de puerta trasera : Implantación de una puerta trasera durante el desarrollo del modelo, que el atacante puede explotar posteriormente.
- Estos ataques requieren un conocimiento profundo de la arquitectura y los parámetros del modelo y, potencialmente, acceso al proceso de capacitación.
- Ataques de caja negra (el atacante tiene conocimiento y acceso limitados o nulos):
- Ataques adversarios : creación de muestras de entrada diseñadas para que el modelo las clasifique o interprete erróneamente.
- Ataques de inversión y reconstrucción de modelos : no requieren conocimiento del funcionamiento interno del modelo.
- Ataques de inferencia de membresía y propiedad : basados en la salida del modelo a ciertas entradas, sin conocimiento de su estructura interna.
- Extracción de datos de entrenamiento : extracción de información sobre los datos de entrenamiento a través de una amplia interacción con el modelo.
- Robo o extracción de modelos : replicar la funcionalidad del modelo observando sus entradas y salidas.
TRASCENDENCIA:
- Los ataques en fase de entrenamiento a menudo requieren acceso interno o una violación significativa en la tubería de datos, lo que los hace menos comunes pero potencialmente más devastadores.
- Los ataques de fase de inferencia son más accesibles para los atacantes externos, ya que a menudo pueden ejecutarse con un acceso mínimo al modelo.
- Los ataques de caja blanca suelen ser más sofisticados y requieren un mayor nivel de acceso y conocimiento, a menudo limitados a personas internas o a través de importantes violaciones de seguridad.
- Los ataques de caja negra son más comunes en escenarios del mundo real, ya que pueden ejecutarse con un conocimiento limitado sobre el modelo y sin acceso directo a sus componentes internos.
Comprender estas categorías ayuda a diseñar estrategias de defensa específicas para cada tipo de ataque, según las vulnerabilidades específicas y las etapas operativas del sistema de IA.
HACKEAR CHATGPT
El modelo ChatGPT AI, como cualquier sistema avanzado de aprendizaje automático, es potencialmente vulnerable a varios ataques, incluidos ataques a la privacidad y la integridad. Exploremos cómo estos ataques podrían usarse o se han usado contra ChatGPT, centrándonos en los ataques a la privacidad mencionados anteriormente:
- Ataques de inversión de modelos :
- Uso potencial contra ChatGPT : un atacante podría intentar utilizar las respuestas de ChatGPT para inferir detalles sobre los datos con los que fue entrenado. Por ejemplo, si ChatGPT proporciona constantemente información detallada y precisa sobre un tema específico y menos conocido, podría indicar la presencia de datos sustanciales de capacitación sobre ese tema, lo que podría revelar la naturaleza de las fuentes de datos utilizadas.
- Ataques de inferencia de membresía :
- Uso potencial contra ChatGPT : este tipo de ataque podría intentar determinar si un texto o tipo de texto en particular formaba parte de los datos de entrenamiento de ChatGPT. Al analizar las respuestas del modelo a consultas específicas, un atacante podría adivinar si ciertos datos se incluyeron en el conjunto de entrenamiento, lo que podría ser una preocupación si los datos de entrenamiento incluyeran información confidencial o privada.
- Extracción de datos de entrenamiento :
- Uso potencial contra ChatGPT : dado que ChatGPT genera texto basado en patrones aprendidos de sus datos de entrenamiento, existe un riesgo teórico de que un atacante pueda manipular el modelo para generar segmentos de texto que se parezcan mucho o repliquen partes de sus datos de entrenamiento. Esto es particularmente delicado si los datos de entrenamiento contenían información confidencial o de propiedad exclusiva.
- Ataques de reconstrucción :
- Uso potencial contra ChatGPT : similar a la inversión del modelo, los atacantes podrían intentar reconstruir los datos de entrada (como ejemplos de texto específicos) en los que se entrenó el modelo, en función de la información que el modelo proporciona en sus resultados. Sin embargo, dado el vasto y diverso conjunto de datos en el que se entrena ChatGPT, reconstruir datos de entrenamiento específicos puede ser un desafío.
- Ataques de inferencia de propiedad :
- Uso potencial contra ChatGPT : los atacantes podrían analizar las respuestas de ChatGPT para inferir propiedades sobre sus datos de entrenamiento que no estén modeladas explícitamente. Por ejemplo, si el modelo muestra sesgos o tendencias en ciertas respuestas, podría revelar información no deseada sobre la composición o naturaleza de los datos de entrenamiento.
- Robo o extracción de modelos :
- Uso potencial contra ChatGPT : esto implica consultar extensamente ChatGPT para comprender sus mecanismos subyacentes y luego usar esta información para crear un modelo similar. Un ataque de este tipo sería un intento de replicar las capacidades de ChatGPT sin acceso al modelo original ni a los datos de entrenamiento.
Los ataques a la integridad de modelos de IA como ChatGPT tienen como objetivo comprometer la precisión y confiabilidad de los resultados del modelo. Examinemos cómo estos ataques podrían usarse o se han usado contra el modelo ChatGPT, categorizados por la etapa de aprendizaje y el conocimiento del atacante:
ATAQUES DURANTE LA FASE DE ENTRENAMIENTO (WHITE-BOX):
- Envenenamiento de datos : si un atacante obtiene acceso al proceso de capacitación, podría introducir datos maliciosos en el conjunto de capacitación de ChatGPT. Esto podría distorsionar la comprensión y las respuestas del modelo, llevándolo a generar contenido sesgado, incorrecto o dañino.
- Ataques de puerta trasera : una persona con información privilegiada o alguien con acceso al proceso de capacitación podría implantar una puerta trasera en ChatGPT. Esta puerta trasera podría desencadenar respuestas específicas cuando se detecten ciertas entradas, que podrían usarse para difundir información errónea u otro contenido dañino.
ATAQUES DURANTE LA FASE DE INFERENCIA (CAJA NEGRA):
- Ataques adversarios : consisten en presentar a ChatGPT entradas especialmente diseñadas que provocan que produzca resultados erróneos. Por ejemplo, un atacante podría encontrar una manera de formular preguntas o indicaciones que confundan constantemente al modelo y le hagan dar respuestas incorrectas o sin sentido.
- Manipulación de salida : esto implicaría interceptar y alterar las respuestas de ChatGPT después de que se generan pero antes de que lleguen al usuario. Si bien esto es más un ataque al canal de comunicación que al modelo en sí, aún puede socavar la integridad de los resultados de ChatGPT.
IMPLICACIONES Y ESTRATEGIAS DE DEFENSA:
- Durante la formación : Garantizar la seguridad y la integridad de los datos y el proceso de formación es fundamental. Las auditorías periódicas, la detección de anomalías y las prácticas seguras de manejo de datos son esenciales para mitigar estos riesgos.
- Durante la inferencia : un diseño de modelo sólido para resistir las entradas del adversario, el monitoreo continuo de las respuestas y las arquitecturas de implementación seguras pueden ayudar a defenderse contra estos ataques.
EJEMPLOS E INQUIETUDES DEL MUNDO REAL:
- Hasta la fecha, no se han divulgado públicamente casos de ataques de integridad exitosos específicamente contra ChatGPT. Sin embargo, existe la posibilidad de que se produzcan tales ataques, como lo demuestran las investigaciones académicas y industriales sobre las vulnerabilidades de la IA.
- OpenAI, el creador de ChatGPT, emplea varias contramedidas como desinfección de entradas, monitoreo de resultados del modelo y actualización continua del modelo para abordar nuevas amenazas y vulnerabilidades.
En conclusión, si bien los ataques a la integridad representan una amenaza importante para los modelos de IA como ChatGPT, una combinación de estrategias de defensa proactivas y vigilancia continua es clave para mitigar estos riesgos.
Si bien estos tipos de ataques se aplican ampliamente a todos los sistemas de IA generativa, el informe señala que algunas vulnerabilidades son particularmente pertinentes para arquitecturas de IA específicas, como los sistemas de modelos de lenguaje grande (LLM) y de generación aumentada de recuperación (RAG). Estos modelos, que están a la vanguardia del procesamiento del lenguaje natural, son susceptibles a amenazas únicas debido a sus complejas capacidades de generación y procesamiento de datos.
Las implicaciones de estas vulnerabilidades son vastas y variadas y afectan a industrias que van desde la atención sanitaria hasta las finanzas e incluso la seguridad nacional. A medida que los sistemas de IA se integran más en la infraestructura crítica y las aplicaciones cotidianas, la necesidad de medidas sólidas de ciberseguridad se vuelve cada vez más urgente.
El informe del NIST sirve como un llamado de atención para que la industria de la inteligencia artificial, los profesionales de la ciberseguridad y los formuladores de políticas prioricen el desarrollo de mecanismos de defensa más sólidos contra estas amenazas emergentes. Esto incluye no sólo soluciones tecnológicas sino también marcos regulatorios y directrices éticas para regir el uso de la IA.
En conclusión, el informe es un recordatorio oportuno de la naturaleza de doble filo de la tecnología de inteligencia artificial. Si bien ofrece un inmenso potencial de progreso e innovación, también trae consigo nuevos desafíos y amenazas que deben abordarse con vigilancia y previsión. A medida que seguimos ampliando los límites de lo que la IA puede lograr, garantizar la seguridad y la integridad de estos sistemas sigue siendo una preocupación primordial para un futuro en el que la tecnología y la humanidad puedan coexistir en armonía.
El cargo 11 formas de hackear ChatGpt y sistemas de IA generativa apareció primero en Noticias de seguridad informática, ciberseguridad y hacking.
Ver Fuente
No hay comentarios.:
Publicar un comentario